
 W poprzednim artykule dotyczącym odpowiedniego podejścia do czytania wspomniałem o listach frekwencyjnych. O ile w przypadku bardziej popularnych języków, takich jak angielski, nie ma większego problemu z ich znalezieniem, o tyle, gdy masz do czynienia z czymś bardziej egzotycznym, twoje szanse na sukces drastycznie maleją. Na szczęście istnieją sposoby na obejście tej przeszkody, choć wymagają one pewnej dozy kreatywności. Gdy już będziesz miał to za sobą, możesz śmiało przejść do efektywnego wykorzystywania opisanych tu metod.
W poprzednim artykule dotyczącym odpowiedniego podejścia do czytania wspomniałem o listach frekwencyjnych. O ile w przypadku bardziej popularnych języków, takich jak angielski, nie ma większego problemu z ich znalezieniem, o tyle, gdy masz do czynienia z czymś bardziej egzotycznym, twoje szanse na sukces drastycznie maleją. Na szczęście istnieją sposoby na obejście tej przeszkody, choć wymagają one pewnej dozy kreatywności. Gdy już będziesz miał to za sobą, możesz śmiało przejść do efektywnego wykorzystywania opisanych tu metod.
Zacznijmy od tego, co można zrobić w sytuacji, gdy nigdzie nie można znaleźć żadnej listy popularnych słów. Jest na to pewien sposób, który polega na stworzeniu jej samemu. Proces ten należy zacząć od znalezienia jakiegoś długiego tekstu lub zebraniu w całość kilkunastu artykułów. Jeśli ich liczba nie będzie zbyt duża, to stworzona lista wciąż będzie użyteczna, choć już nieco mniej. Gdy natomiast wybierze się teksty dotyczące jakiegoś jednego ogólnego tematu, to w rezultacie uzyska się uproszczony wykaz terminologii używanej w danej dziedzinie.
Następnie należy zapisać wspominanie teksty w pliku .txt, używając do tego celu Worda lub systemowego notatnika. Trzeba jednak pamiętać, żeby zmienić kodowanie na UTF-8. W tym pierwszym robi się tak, wybierając "Zapisz jako…", wpisując nazwę pliku i ją zatwierdzając. Potem wyświetli się okno, w którym trzeba zaznaczyć pole "Inne kodowanie", a na końcu "Unicode (UTF-8)". W notatniku natomiast wystarczy nacisnąć "Zapisz jako…" w menu "Plik", wybrać odpowiednie kodowanie z rozwijanej listy i zatwierdzić. Dzięki temu uniknie się problemów z wyświetlaniem różnych znaków (np. chińskich).
Tworzenie listy
Kolejnym krokiem jest pobranie programu AntConc ze strony Lawrence'a Anthony'ego. Po jego ściągnięciu nie trzeba niczego instalować, wystarczy tylko, że otworzysz dwukrotnym kliknięciem ściągnięty plik, a pojawi się okno programu. Następnie powinieneś wybrać z menu "Global Settings" zakładkę "Character Encoding", zaznaczyć "UTF-8" i kliknąć "Apply". Teraz wystarczy, że wczytasz plik lub pliki z tekstami, wchodząc w menu "File", a następnie "Open File(s)…" i wybierając to, co cię interesuje. Dzięki widocznej z boku liście możesz zaznaczać, które pliki mają być w danej chwili poddawane analizie.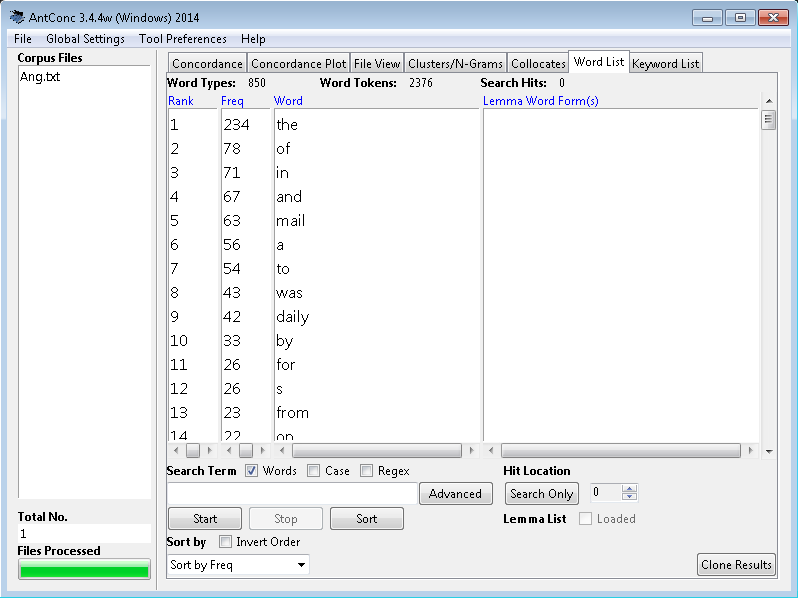
Gdy już przygotowałeś materiał źródłowy, czas wreszcie zabrać się za jego przetwarzanie. Należy w tym celu przejść na zakładkę "Word List" i wcisnąć przycisk "Start". Pojawi się wtedy poszukiwana przez ciebie lista słów domyślnie uporządkowana według częstotliwości występowania. Na tym etapie można już wyeksportować ją do pliku tekstowego, klikając menu "File" i wybierając opcję "Save output to text file…". Otrzymasz wtedy listę z wyszczególnionymi danymi na temat pozycji i liczby wystąpień. Niestety program nie potrafi jak na razie rozpoznać wyrazów nieoddzielonych spacjami, więc odpada używanie go przy językach składających się z dużych zbitek wyrazowych np. w chińskim. Posiada jednak funkcję pokazywania kontekstu, która pojawia się po kliknięciu na jakieś słowo z listy. Polecam poeksperymentowanie z jego możliwościami na podstawie instrukcji ze strony twórcy tego narzędzia.
Uzupełnianie o dodatkowe informacje
Przejdźmy teraz do tego, jak możesz wykorzystać uzyskany zbiór. Na tym etapie posiadasz tylko listę mniej lub bardziej obcobrzmiących wyrazów. Dobrym pomysłem będzie więc uzupełnienie go o przykładowe zdania ilustrujące znaczenie oraz ich przetłumaczone wersje. Powinny być one dobrane tak, aby ich długość i trudność gramatyczno-leksykalna nie przekraczała rozsądnego limitu, który każdy powinien wyznaczać sobie indywidualnie. W przypadku gotowych list frekwencyjnych jest to jedyna rzecz, którą trzeba zrobić. Jeśli zaś chodzi dostarczane wraz z nimi tłumaczenia pojedynczych słówek, to równie dobrze mogłoby ich nie być, ponieważ w większości przypadków, to kontekst decyduje o tym, jakie znaczenie zostało użyte w danej sytuacji.
W czasie pracy z hasłami może pojawić się pytanie, skąd brać pasujące przykładowe zdania. Jest kilka różnych rozwiązań tego problemu. Według jednej z opinii powinno się używać wyszukiwarki Google, sprawdzając rezultaty, które pojawią się po wpisaniu danego wyrazu lub frazy. Nie zgadzam się z tym podejściem. Według mnie prowadzi to do utrwalenia błędnych konstrukcji językowych i zapamiętania niepoprawnych przykładów użycia słownictwa. Rozsądniejszą alternatywą wydaje się wybieranie zdań dostępnych za darmo w renomowanych słownikach online lub używanie wyszukiwarki Google Books, która przeszukuje zasoby książkowe będące przynajmniej w teorii pozbawione rażących błędów. Inną opcją jest wykorzystanie korpusów językowych, które można dość łatwo znaleźć w Internecie. Najlepiej zacząć poszukiwania w jego anglojęzycznej części lub wpisać zapytanie w języku docelowym. Można też ewentualnie skorzystać z wyszukiwarek dostępnych na stronach popularnych gazet internetowych, które posiadają papierowe wydania. Są bowiem zazwyczaj lepiej sprawdzone niż publikacje na innych stronach internetowych.
Optymalizowanie nauki
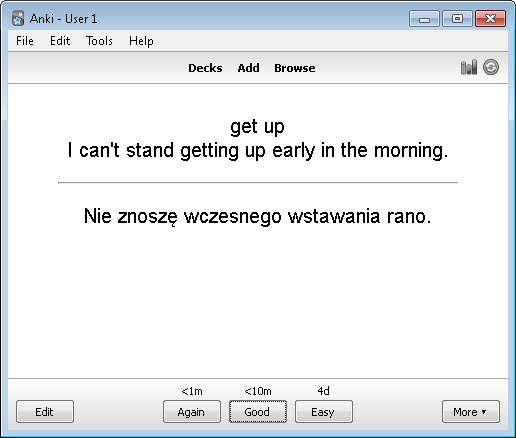
Obrobione hasła najlepiej jest wpisywać od razu do programu Anki, który pomaga w optymalizowaniu powtórek materiału do nauki. Wyznacza on je akurat wtedy, gdy prawie nie pamiętasz tego, czego uczyłeś się wcześniej. Nie należy jednak przesadzać z ilością tekstu wpisanego do pojedynczej pary pytanie-odpowiedź, ponieważ może to prowadzić do utraty motywacji. Lepiej sprawdza się tu rozbicie różnych znaczeń i użyć danego wyrazu na kilka kart i zilustrowanie ich odpowiednimi zdaniami. Jeśli nie zgadzasz się z poglądem zalecającym takie dawkowanie wiedzy, to możesz ściągnąć sobie w ramach testu bazę, która jest w zasadzie przerobionym słownikiem frekwencyjnym Oxford 3000. Mam jednak duże wątpliwości co do jej faktycznej przydatności.
Refleksje
Przedstawione powyżej porady pozwolą ci na skuteczne stworzenie i wykorzystanie potencjału list frekwencyjnych. Oczywiście nie jest to rozwiązanie idealne, dlatego polecam wprowadzanie do niego własnych poprawek. Gorąco zachęcam też do korzystania z programu AntConc, bo kryje on w sobie wiele ciekawych funkcji, które docenią osoby pasjonujące się rozkładaniem języka na części. Jeśli natomiast chodzi o Anki, to nie przeceniałbym tego narzędzia. Poznałem bowiem takie osoby, które polegają na mnemotechnicznym robieniu powtórek materiału całkowicie z pamięci, czego efektywność potwierdzają odkrycia naukowe z ostatniej dekady.
Zobacz także:
9 kluczowych pytań na temat ANKI
Wyznania ANKIoholika
Jak czytać i nie zwariować
Jakie materiały warto czytać?
Lista frekwencyjna jest banalna w przygotowaniu w przypadku języka angielskiego, gdzie słowa praktycznie nie podlegają odmianie, natomiast w przypadku np. rosyjskiego wymaga znacznie więcej roboty.
Do angielskiego bym wygooglał Ogden-simple English-ma to około 1800słów chyba i jest gotowe tylko zabrać z www i użyć.
Dzięki za ten tekst – nawet nie wiedziałam, że istnieje atki programik jak AntConc. Dzięki wielkie! 🙂
Dostałem dziś olśnienia, do czego może mi posłużyć opisywany przez Ciebie program AntConc. Kilkanaście lat temu policzyłem różnorodność słów w moich mailach po angielsku w zestawieniu do dwóch native speakerek z USA w tym samym ciągu korespondencji. Ze zmutkiem stwierdziłem, że używam mniejszej ilości różnych słów w tekście tej samej długości… 🙂 Tylko, że wówczas pracowicie liczyłem słowa "ręcznie", teraz zaś myślę o tym, by zastosować AntConc do analizy np. zapisów moich chatów z kilkoma rodzimymi użytkownikami hiszpańskiego na sporo większej próbce (ewentualnie odpowiednio dostosowanej np. przez poprawę literówek, jeśli nie chcę analizować pisania, a słownictwo) i być może keczua. Ponieważ teksty będą pochodzić z dialogów/korespondencji, zapewnioną mam jedność tematyki i rejestru po obu stronach. Chciałbym stwierdzić czy istnieją różnice pomiędzy nami w użyciu słownictwa i jakie to są różnice.
Podana przez Ciebie informacja o kodowaniu w notatniku jest bardzo przydatna, bo bez tego wychodzą bzdury.
Czesc, pisze prace magisterska i jestem zagubiona……pracuje na korpusie jezyka francuskiego, mam korpus w notatnik, zakodowany na utf-8. taki tez mam ustawiony na global settings w antconcu. i dalej nie dziala, tekst jest pelen dziwnych znakow, nie moge pracować. Czy wiesz może o co chodzi? Bede bardzo wdzieczna.
Zapisałem sobie przykładowy plik po francusku w tym kodowaniu i wszystko wydaje się działać. Sprawdzałem na wersji 3.4.4w. Może być wiele innych przyczyn takiego problemu. Mogłaby mi Pani wysłać ten plik do testów na adres: kontaktswiedza@gmail.com ? Tak wyeliminuję jedną z ewentualności.
Doszedłem ostatnio do wniosku, że AntConc jest na drugim miejscu po Anki najużyteczniejszym programem do nauki języków obcych, jaki znam (chyba, że będziemy wliczać tu również słowniki, ale z nich korzystam online). Artykuł o AntConc zasługuje na więcej uwagi niż otrzymał sądząc po liczbie komentarzy w przeciągu ponad 5 lat.
Jednak w rzeczywistości to nie funkcja tworzenia list frekwencyjnych okazała się być dla mnie cenna, a pozostałe z dostępnych zakładek w AntConc. Anki używam do powtórki słownictwa, AntConc tymczasem używam do rozwiewania wątpliwości zasadniczo gramatycznych.
Ze źródeł wysokiej jakości utworzyłem sobie korpus języka hiszpańskiego, tj. taki folder z bardzo wieloma plikami .txt., gdzie typowy plik zatytułowany jest według wzoru państwo, rok, autor, tytuł, czyli np.:
"[Colombia, 1867] Jorge Isaacs – María.txt"
Teraz jeśli interesuje mnie użycie jakiegoś słowa, albo jakiegoś wyrażenia, wpisuję je w zakładce Concordance, po czym wyświetla się lista zdań ze wszystkimi przypadkami jego użycia w korpusie na kolorowo wyróżnionymi. Biorąc jakiś prosty przykład z języka hiszpańskiego, przypuśćmy, że chciałbym sprawdzić możliwą różnicę użycia pomiędzy "en vez de", a "en lugar de", to mogę w zakładce Concordance sobie zdania z tymi konstrukcjami wyświetlić i porównać. Następnie przechodząc do zakładki Concordance Plot mogę znacznie czytelniej zobrazować częstość użycia tych konstrukcji w zależności od źródła (wpierw właściwie zatytułowałem źródła: plik zaczyna się od państwa, potem roku) – tak np. widzę, że pierwsza z tych konstrukcji liczniej występuje w książkach do połowy XX wieku, a druga z tych konstrukcji liczniej występuje w książkach współczesnych (tytułując źródła w ten sposób z datą z początku słupki wyświetlają się chronologicznie, co znacznie ułatwia analizę); podobnie można analizować np. różnice dialektalne, albo jakieś inne–zależy jak zbudujemy korpus i zatytułujemy pliki, bo może być to np. mowa vs pismo. Następnie po kliknięciu w któryś z przypadków użycia (kreska na słupku) otwiera się kolejna zakładka File View, gdzie można ten przypadek zobaczyć bezpośrednio w pliku.
Są też zakładki Clusters/N-Grams oraz Collocates, z których co prawda nie korzystam, ale również mogą być użyteczne, no i oczywiście Word List, czyli lista frekwencyjna.
Analiza własnego korpusu zbudowanego z sensownych źródeł, zawierających tego rodzaju język (np. dialekt, styl, tematyka), jaki mnie konkretnie interesuje, ma dla mnie więcej sensu niż wpisywanie wyrażeń w wyszukiwarce internetowej i czytanie dzikich przykładów zdań napisanych przez kogoś w necie. Oczywiście nic nie stoi na przeszkodzie, by stworzyć korpus np. z jakiejś formy języka mówionego choćby wrzucając do korpusu napisy do filmów (oryginalne, nie tłumaczone), jeśli się do takich dorwiemy. AntConc to bardzo fajna sprawa–dowolny wyraz lub wyrażenie, co do którego użycia mamy jakieś wątpliwości, można bardzo łatwo wybadać, tj. wyświetlić wszystkie zdania z tym wyrażeniem, albo też porównać częstotliwość jego użycia w zależności od typu źródła.
W ten sposób zasadniczo używam programu AntConc. Mam kilka zastrzeżeń do funkcjonowania AntConc na Linuxie, ale tych kilka robali łatwo jest obejść i nie uniemożliwiają używania programu.