
 Wstęp
Wstęp
W poprzednim artykule wspomniałem o kilku narzędziach służących do nauki języka szwedzkiego, a o których niewiele się mówi. Ich wygląd może na pierwszy rzut oka odstraszać przeciętnego użytkownika, ale po ujarzmieniu kilku podstawowych "chwytów" da się z nich wiele wyciągnąć i zwiększyć produktywność nauki języka szwedzkiego. Jeśli jesteś studentem językoznawstwa lub jeśli planujesz zajmować się językoznawstwem szwedzkim – zapraszam. Jeśli uczysz się szwedzkiego, ale poznane wcześniej metody nauki nie przyniosły rezultatu, a szukasz czegoś wyjątkowego (a nawet niszowego i hipsterskiego) – zapraszam do lektury.
Korp
Korp jest zaawansowanym narzędziem do przeszukiwania baz tekstowych zwanych również korpusami. Jest jednym z wielu genialnych narzędzi oferowanych przez „szwedzką część Internetu”, które mogą być nieocenioną pomocą szczególnie dla osób bardziej zaawansowanych i samodzielnych, które zdążyły już opanować podstawy leksyki i które są w stanie posługiwać się bardziej złożonymi strukturami gramatycznymi; piję tu oczywiście do studentów filologii wyższych lat jak również i tych, dla których obcowanie z literaturą (piękną, faktu) nie jest ostateczną ostatecznością. Chciałbym pokazać, że przedzieranie się przez korpusy może być frajdą. Naszą fascynującą przygodę zacząć wypada od krótkiego zaprezentowania interfejsu między użytkownikiem końcowym (nami) a bazą danych.
Po wprowadzeniu adresu w przeglądarce (patrz przypisy), ukaże nam się dość rozbudowana strona z wieloma kontrolkami i formularzami. Nas interesuje przede wszystkim pole szukania i przycisk “Sök”. Panel wyszukiwana składa się z dwóch zasadniczych części: wspomnianego formularza i części poniżej, gdzie wyświetlać się będą wyniki (o ile szukana fraza zostanie odnaleziona). Dostępne są trzy rodzaje wyszukiwania: „enkel” (proste), „utökad” (rozszerzone) i „avancerad” (zaawansowane). W tym artykule zajmiemy się pierwszymi dwoma, jako że wyszukiwanie zaawansowane przeznaczone jest do bardziej wysublimowanych zastosowań, wymaga ponadto znajomości specjalnego języka zapytań (sprawdza się to na przykład w przypadku pisania własnych interfejsów lub aplikacji korzystających z API serwisu).
Wyszukiwanie proste
Ten rodzaj zapytań polega na przeszukiwaniu bazy pod kątem pojedynczych lub wielu słów. Można również wyszukiwać wszystkie formy fleksyjne określonych wyrazów i związków wyrazowych, np. po wpisaniu „katt” należy odczekać chwilę, po czym system proponuje nam zwięzła listę rozwijaną zawierającą dostępne formy i kolokacje:
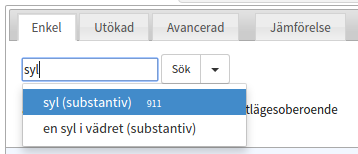
Po skorzystaniu z tej opcji, po prawej stronie ukazać się winno pole zatytułowane „Relaterade ord” z nazwą korpusu. Po kliknięciu w nie pojawi się małe okno z linkami do wpisów, które system uznał za podobne. Przyznam szczerze, że ta funkcjonalność wygląda mi raczej na wczesną fazę testów – system często proponuje słowa zupełnie na pierwszy rzut oka przypadkowe, choć może kryje się za tym jakiś większy sens, którego nie jestem w stanie pojąć.
Poniżej pola tekstowego dostępne są jeszcze inne opcje. Dwie pierwsze, w oczywisty sposób pokrewne, służą do wyszukiwania słów, w których to podane jest pierwszym lub ostatnim członem złożenia. Trzecia opcja, kryjąca się pod tajemniczą nazwą „skiftlägesoberoende”, sprawia, że system analizując nasze zapytanie, nie przejmuje o wielkością użytych liter: “katt”, “Katt”, “kAtT” będą traktowane jednakowo.
Wyszukiwanie rozszerzone
Ta zakładka udostępnia nam zdecydowanie bardziej zaawansowane metody szukania. Każda szara ramka odpowiada jednemu tokenowi. Dla każdego tokenu dobrać możemy odpowiednie kryteria. Aby dodać kolejny token, kliknąć należy na mały plus znajdujący się zawsze na prawo od ostatniej ramki z tokenem. Każdy token ma również przycisk w formie iksa, którym możemy go usunąć. Ciekawą opcją jest również zmienianie kolejności wyrażeń – aby tego dokonać, należy upuścić myszką token we wskazane miejsce.
Kryteria wybieramy z pokaźnej listy podzielonej na atrybuty leksykalne i tekstowe. Możemy zaznaczyć między innymi część mowy, formę podstawową, relację zależności (część zdania) i “msd”/“morfosyntaktisk beskrivning” (opis morfosyntaktyczny). Z kolejnej listy wybieramy istotę relacji: jest, nie-jest, zaczyna-się-na, zawiera, kończy-się-na, wyrażenie regularne i zaprzeczone wyrażenie regularne.
W dolnej części ramki znajduje się również koło zębate, gdzie zaznaczyć można zakotwiczenie tokenu:
- Powtarzaj – tu określamy minimalną i maksymalną ilość powtórzeń danego tokenu w wybranej jednostce.
- Początek zdania – zakotwiczenie na początku zdania.
- Koniec zdania – zakotwiczenie na końcu zdania.
Warto dodać, że możemy użyć kilku “kotwic” jednocześnie. Usuwamy je oczywiście za pomocą iksa.
Lärka
Lärka (adres w przypisach) jest opisywana przez swoich twórców jako narzędzie do nauki języka szwedzkiego za pomocą danych korpusowych. Nie jest niczym więcej jak kolejnym interfejsem do baz leksykalnych, którego głównym zadaniem jest losowanie zdań i przekształcanie ich na zadania z lukami. Puste miejsca uczeń zastępuje poprawną odpowiedzią. Sesje w Lärce są nieskończone. Rodzaj luk wybiera użytkownik.
Wygląd strony śmierdzi trochę początkami Internetu. Na szczęście formularze są łatwe w użyciu, przez co całą stronę można zaprogramować w prosty sposób. Nas interesuje przede wszystkim górna belka, poniżej wizerunku skowronka (wdzięcznie brzmiące słowo lärka oznacza właśnie ten gatunek). Z pierwszej listy po lewej stronie wybrać możemy jeden z dwóch dostępnych trybów: test dla studentów językoznawstwa lub test dla (zwykłych) uczących się. Po wybraniu interesującego nas trybu ukażą się dodatkowe opcje konfiguracyjne. O dziwo, tryb dla zwykłego śmiertelnika jest o bardziej rozbudowany niż w przypadku opcji dla studentów językoznawstwa.
Opcje i wygląd sesji
Jako pierwszą rzecz wybieramy zakres, jakiego dotyczyć ma nauka. Dostępne są następujące opcje:
- Znajomość słownictwa (jako test wielokrotnego wyboru),
- Znajomość fleksji (również test wielokrotnego wyboru),
- Znajomość ortografii.
Następną grupę ustawień stanowi wybór list słownictwa, którego chcielibyśmy się nauczyć. Warto dodać, że listy te korzystają z tych samych baz, co Korp. Dodatkowo listy tematyczne są sprzężone ze słownikiem Lexin (wspaniały szwedzki słownik jednojęzyczny). Dalej wybrać możemy część mowy (tu należy uważać, obowiązuje bowiem podział na części mowy zgodnie z SAG – Svenska Akademiens Grammatik, który może odbiegać nieco od tego, którego zwykło się uczyć w polskich szkołach). Kolejną niezwykle użyteczną opcją jest wybór trudności testu zgodnie z poziomem biegłości językowej ustalonym przez Radę Europy.
Do listy, która znajduje się po prawej stronie górnej belki, dodać można słowa do podręcznej listy, która później zostanie uwzględniona przez algorytm losujący.
W ramce, gdzie odbywa się wybieranie z odpowiedzi, widoczna jest również tabela z krótkim podsumowaniem dotyczącym poprawności wprowadzonych odpowiedzi podczas bieżącej sesji. Dodatkowo, przy każdym zdaniu kolorowe, „klikalne” ikonki kierują do pomocnych podstron serwisu – syntezy mowy, odpowiedzi zakodowanej w formacie JSON (dla programistów) oraz rozbioru zdania na czynniki pierwsze: części mowy ze wskazaniem fraz poprzez zamieszczenie różnokolorowych klamer poniżej określeń:

Zakończenie
Mam nadzieję, że ten artykuł zachęcił Was do własnych poszukiwań i że dzięki niemu dacie szansę majestatycznemu krukowi i potężnemu skowronkowi. Zachęcam do zadawania pytań!
Przypisy:
http://spraakbanken.gu.se/korp – Korp
http://spraakbanken.gu.se/larka – Lärka
Zobacz również:
Po jakiemu uczyć się szwedzkiego?
Pogadanka o szwedzkich kolokacjach
Nie samymi podręcznikami… czyli internetowe pomoce naukowe