 Do napisania tego tekstu zainspirowała mnie scena z jednego z pierwszych odcinków serialu “Wikingowie”. Ragnar i kilku jego kumpli po raz pierwszy natyka się na anglosaskiego rycerza. Próbują się dogadać i zupełnie im to nie wychodzi. “Wikingowie”, mimo tony wad i upchnięcia całego IX wieku w mniej więcej piętnastu latach, jedną rzecz mają dobrze pomyślaną: ludzie z różnych stron świata faktycznie mówią różnymi językami. Jeżeli w tej samej scenie bohaterowie posługują się dwoma językami, współczesny angielski zastępuje tylko jeden z nich, podczas gdy ten drugi pozostaje w oryginale (no, mniej więcej w oryginale — na tyle, na ile udało się go zrekonstruować).
Do napisania tego tekstu zainspirowała mnie scena z jednego z pierwszych odcinków serialu “Wikingowie”. Ragnar i kilku jego kumpli po raz pierwszy natyka się na anglosaskiego rycerza. Próbują się dogadać i zupełnie im to nie wychodzi. “Wikingowie”, mimo tony wad i upchnięcia całego IX wieku w mniej więcej piętnastu latach, jedną rzecz mają dobrze pomyślaną: ludzie z różnych stron świata faktycznie mówią różnymi językami. Jeżeli w tej samej scenie bohaterowie posługują się dwoma językami, współczesny angielski zastępuje tylko jeden z nich, podczas gdy ten drugi pozostaje w oryginale (no, mniej więcej w oryginale — na tyle, na ile udało się go zrekonstruować).
Podczas pierwszych spotkań Skandynawowie i Anglosasi rozmawiają więc przez tłumacza. Jest to jednak dość niezręczne pod względem płynności gry aktorskiej, dość szybko więc Ragnar stwierdza, że już się nauczył mówić w języku wroga (dzięki pomocy Athelstana, anglosaskiego mnicha, którego porwał) i głównym językiem scen w Anglii staje się właśnie staroangielski.
Ale na ile pokrewieństwo tych języków mogło pomóc przybyszowi ze Skandynawii w opanowaniu staroangielskiego? Jak bardzo różniły się one od siebie? Z jednej strony, obydwa należą do rodziny germańskiej, z drugiej jednak przez setki lat rozwijały się w izolacji od siebie. A skoro już przy tym jesteśmy, jak mają się one do innych języków germańskich, zwłaszcza niemieckiego?
Zanim odpowiemy na te pytania, chciałbym napisać kilka słów wstępu o sprawach, które w sumie każdy powinien coś wiedzieć, ale gdy w ramach zbierania danych do tego tekstu zacząłem czytać dyskusje na tematy językowe w polskim internecie, odkryłem, że chyba jednak nie.
Ewolucja języków w pewnym stopniu przypomina ewolucję biologiczną [1]. Tak jak ona ma charakter grupowy, nie indywidualny (tzn. zmiany zachodzą w ramach całej lokalnej populacji) i działa w stosunkowo odizolowanych społecznościach. Zmiany są na tyle powolne, że kolejne pokolenia nie mają problemu z porozumiewaniem się między sobą i w dużej mierze nie zdają sobie z nich sprawy. Przed okresem nowożytnym standaryzacja języka, czyli świadome wprowadzanie i zatwierdzanie słownictwa i reguł gramatycznych przez grupę ludzi o dużym autorytecie, miała miejsce bardzo rzadko i dotyczyła w zasadzie wyłącznie języków o wysokim statusie religijnym i kulturowym (łacina, sanskryt), podczas gdy większość społeczeństwa posługiwała się nieuregulowanymi dialektami. Poza tymi rzadkimi przypadkami rozwój języków nie był z góry zaplanowany. Zmiany wymowy zachodziły niemalże nieświadomie: nikt nigdy nie obudził się rano i nie stwierdził, że np. od teraz przestaje wymawiać samogłoski nosowe. Podobnie zmiany w gramatyce wynikały z nieperfekcyjnego przekazu pomiędzy pokoleniami, co owocowało powstawaniem nowych wyjątków od reguł gramatycznych oraz następnie upowszechniania się tych wyjątków, a stopniowego wycofywania starych reguł. Również zapożyczenia z języków sąsiadów miały więcej wspólnego z modą i trendami w lokalnej kulturze, niż z racjonalnymi decyzjami, jak by to chcieli niektórzy językoznawcy-amatorzy na blogach i w mediach społecznościowych.
Rodzina języków germańskich ma swoje korzenie na terytorium współczesnej Danii i południowej Szwecji, gdzie przodkowie ludów germańskich żyli w relatywnej izolacji od momentu oddzielenia się ich od innych grup indoeuropejskich, aż po ok. 500 r. p.n.e. [2] Pod koniec tego okresu możemy wyróżnić dwie główne podgrupy językowe: północną (w Skandynawii) i zachodnią (w obecnych północnych Niemczech). Jest to jednak wszystko trochę palcem po wodzie pisane. Zakładamy, że tak było, ponieważ wykopaliska archeologiczne wskazują na osadnictwo w tych czasach w tym rejonie, a badania lingwistyczne sugerują taki właśnie rozwój wypadków pomiędzy rekonstruowanym językiem praindoeuropejskim z jednej strony a językami germańskimi, co do których mamy dowody na piśmie, z drugiej. Nie istnieją jednak żadne pisemne dokumenty mówiące nam cokolwiek o tym hipotetycznym pragermańskim języku ani o jego dialektach.
Nie oznacza to jednak, że dowolna inna hipoteza będzie miała status równy z powyższą teorią. W lingwistyce, podobnie jak w archeologii i w innych dziedzinach, staramy się ograniczać ilość niezwykłych wydarzeń, jakie musiałyby mieć miejsce, aby dana teoria miała sens. Teoria migracji i izolacji jest najlepszym, co obecnie mamy. Ale wróćmy do tematu.
W drugim wieku przed naszą erą zaczęła się ekspansja plemion germańskich na południe, a co za tym idzie częstsze kontakty z Celtami, a następnie z Rzymianami. Zachodnia podgrupa zaczęła się dywersyfikować pod wpływem tych zmian i kontaktów, podczas gdy podgrupa północna nadal rozwijała się w relatywnym spokoju. Paradoksalnie jednak pierwszy znany nam tekst w języku germańskim pochodzi od ludzi, którzy przybyli na południe prosto ze Skandynawii i przez jakiś czas zamieszkiwali tereny współczesnej Polski — Gotów.
Język gocki zaliczamy do osobnej, wschodniej grupy języków germańskich, razem z językami Wandalów i Burgundów — dwóch innych germańskich plemion, które, podobnie jak Goci, najechały Cesarstwo Rzymskie w V wieku n.e. [3] O ich mowie wiemy jednak niewiele, natomiast Goci pozostawili po sobie długie fragmenty tłumaczeń z Nowego Testamentu. U szczytu potęgi, w VI wieku n.e., rządzili współczesną Hiszpanią i Włochami. Nigdy nie było ich jednak wielu i po przegranych wojnach ich potomkowie wtopili się w lokalne społeczności i zapomnieli języka przodków. Istnieją przesłanki, by sądzić, że na Krymie osadnicy goccy dużo dłużej zachowali niezależność kulturową i językową, ale materiałów dowodowych na potwierdzenie tej teorii jest zbyt mało, by przyjąć ją ze stuprocentową pewnością. Wiemy, że Ostrogoci zasiedlali te tereny przed podbojem Rzymu, a w 1562 roku Ogier Ghiselin de Busbecq — ambasador cesarza Ferdynanda I na dworze otomańskim w Konstantynopolu, napisał list, w którym zwrócił uwagę na dziwną mowę, którą posługują się niektórzy mieszkańcy Krymu. Jego notatki sugerują, że mógł to być język wywodzący się z gockiego. Nazywamy go krymskim gockim, ale jak widać, informacje o nim są niepewne.
W czasach gdy Goci zajmowali się dzieleniem między sobą resztek Cesarstwa Rzymskiego, wybrzeże Morza Północnego i Danię zasiedlały plemiona zachodniogermańskie, których języki tworzyły kontinuum. Mieszkańcy sąsiednich wiosek zazwyczaj byli w stanie porozumieć się ze sobą bez problemów, lecz im dalej na wschód lub na zachód, różnice robiły się coraz poważniejsze. Patrząc od zachodu byli to: Frankowie, Fryzowie, Sasi (Saksończycy) i Anglowie. W V wieku n.e. Frankowie wydarli Galię upadającemu Rzymowi. Na podbitych terenach — analogicznie do Gotów we Włoszech i Hiszpanii w trochę wcześniejszym okresie — Frankowie stanowili mniejszość i mimo iż była to mniejszość uprzywilejowana, ich potomkowie stopniowo porzucali język przodków na rzecz lokalnych dialektów romańskich, dając początek starofrancuskiemu. Frankijski był jeszcze w użyciu w czasach Karola Wielkiego (742-814), ale stopniowo zmieszał się z lokalnymi dialektami romańskimi, dając początek starofrancuskiemu. Nie był to proces zupełnie jednostronny: w jego wyniku język starofrancuski zyskał domieszkę słów pochodzenia germańskiego, wymawiane /h/ na początku słów tego pochodzenia oraz być może również nasalizację (głoski /ɑ̃/, /ε̃/, /œ̃/ oraz /ɔ̃/), tak charakterystyczną dla tego języka. [4,5]
Anglowie, Sasi oraz mieszkający na terenach obecnej Danii Jutowie (których podejrzewamy o posługiwanie się językiem z północnej grupy językowej) wykorzystali upadek Cesarstwa do inwazji na Brytanię. Z ich połączonych mocy powstał Kapitan Planeta… czekaj, nie ta bajka… Ich języki dały początek staroangielskiemu. I to na ludzi posługujących się tym właśnie językiem natknęli się wikingowie.
Pod koniec pierwszego tysiąclecia naszej ery języki północnogermańskie również stanowiły kontinuum. Nawet obecnie Norwegowie, Duńczycy, i Szwedzi, są w stanie porozumieć się do pewnego stopnia. Jedynie islandzki, rozwijający się w relatywnej izolacji, pozostał bardziej konserwatywny pod względem słownictwa i gramatyki, a wymowa uległa zmianie w tak odmiennym kierunku, że Islandczykom łatwiej jest dziś czytać stare sagi, niż współczesne skandynawskie kryminały.
Możemy zauważyć tu jeszcze jedną ciekawą zależność. Zmiany w języku nie następują z tą samą szybkością w każdej społeczności, a czas izolacji od wspólnego przodka nie jest jedynym czynnikiem w tym procesie. Olbrzymią rolę gra również kontakt z innymi grupami językowymi oraz wydarzenia historyczne. Pozostawanie na uboczu europejskiej historii pozwoliło Islandczykom na przechowanie przez stulecia archaicznych cech języka. W tym samym czasie Wyspy Brytyjskie stały się areną dla migracji, wojen i stapiania się ze sobą ludów z różnych krańców kontynentu, co pociągnęło za sobą gwałtowny rozwój języka angielskiego.
Wiemy na pewno, że wśród wikingów, którzy najechali Anglię w IX wieku, dominowali ludzie mówiący dialektami zachodnimi języka, który nazywamy staronordyckim. Wiemy o tym języku dość dużo, ale głównie z Islandii i z trochę późniejszego okresu jego rozwoju. Z drugiej strony, staroangielski znamy głównie z poematu “The Seafarer” oraz z “Beowulfa”, również spisanych dopiero sto-dwieście lat po pierwszym spotkaniu Anglosasów z wikingami. Możemy więc zrekonstruować stan obu języków kilkaset lat wcześniej i porównać je. Na początku IX wieku te dwa języki miały za sobą jedynie trzysta-czterysta lat kompletnej separacji, a od wspólnego proto-germańskiego korzenia dzieliło je ok. 1300 lat. Z drugiej strony jednak, podobieństwo słów nie zapewnia jeszcze kompletnego zrozumienia. Zapewne podczas pierwszych kontaktów Skandynawowie i Anglosasi byli w stanie rozpoznać pojedyncze słowa wypowiadane przez drugą stronę, ale brak kontekstu, nieznana wymowa i “fałszywi przyjaciele” uniemożliwiały dokładne zrozumienie bez pomocy tłumacza.
Mogę to porównać do następującej sytuacji: Często w polskim internecie natykam się na stwierdzenie, że ktoś jest w stanie bardzo dobrze zrozumieć inny słowiański język. Zazwyczaj autor takiego stwierdzenia przeczytał tekst w danym języku lub wysłuchał nagrania w wykonaniu wyraźnie mówiącego aktora lub polityka, a następnie miał czas się nad nim zastanowić oraz sprawdzić kilka niejasnych słów. Jest to zupełnie co innego, niż gdy rozmawiasz z kimś w hałaśliwym miejscu i masz zaledwie kilka sekund na zrozumienie wypowiedzi i sformułowanie swoich myśli. Myślę więc, że serial “Wikingowie”, być może przypadkiem, przedstawił spotkanie wikingów z Anglosasami całkiem prawidłowo. Ragnar z początku potrzebował pomocy tłumacza w kontaktach z northumbryjskim królem i jego doradcami, ale z czasem coraz lepiej zdawał sobie sprawę z podobieństw między dwoma językami i nauczenie się staroangielskiego nie było dla niego wielkim problemem.
Terry Pratchett pisał o angielskim, że jest to język, który w ciemnych zaułkach okrada inne języki z gramatyki i słownictwa. Na pewno było tak w przypadku staronordyckiego, z którego do staroangielskiego trafiło bardzo wiele zapożyczeń, zwłaszcza prostych, jednosylabowych słów, opisujących przedmioty codziennego użytku, jak pług (s.nord. plogr, ang. plough) lub ciasto (s.nord. kaka, ang. cake), słowa rozpoczynające się od “sk”, która to zbitka w anglosaskim ewoluowała w “sh”, jak również zaimek trzeciej osoby liczby mnogiej, “they”. Mimo tych zmian język Anglosasów w wieku X nadal nazywamy staroangielskim i dopiero najazd Normanów w wieku XI uznajemy za początek średnioangielskiego.
Normanowie byli potomkami wikingów, którzy na przełomie IX i X wieku osiedlili się w północnej Francji. W roku, 876 jeszcze jako wrogowie króla francuskiego, zdobyli Rouen i przez kolejne dekady atakowali okoliczne miasteczka i wsie, nie napotykając dużego oporu. W 911 ich przywódca, Rollon, zawarł przymierze z królem Karolem III, które zalegalizowało stan faktyczny: ziemie na północnym wybrzeżu Francji weszły w posiadanie “ludzi z północy”, Normanów. Od tego czasu Normandia, mimo iż formalnie pozostawała pod władzą króla Francji, była w praktyce niezależnym organizmem politycznym, który odegrał ważną rolę w historii europejskiego średniowiecza. Normani stosunkowo szybko porzucili staronordycki na rzecz lokalnego starofrancuskiego dialektu (który czasem nazywany jest staronormańskim). Gdy w roku 1066 książę Wilhelm na własną rękę zorganizował udaną inwazję na drugą stronę kanału La Manche, przywiózł już ze sobą język o wyraźnie romańskich cechach.
W ciągu kilku kolejnych setek lat język angielski ewoluował z niezwykłą szybkością, absorbując normańskie słowa. Popularnym przykładem jest tu porównanie par słów: nazw zwierząt hodowlanych oraz przyrządzanego z nich mięsiwa. Klasa rządząca nazywała mięso na swoich stołach słowami pochodzenia normańskiego: mutton (baranina), beef (wołowina), veal (cielęcina); podczas gdy służący mówili o zwierzętach, używając słów anglosaskich: sheep, cow, calf. Do tej pory język angielski pełen jest par synonimów lub słów o podobnym znaczeniu, w których jedno z nich wywodzi się ze staronormańskiego i należy do wyższego rejestru, niż drugie, wyraźnie germańskie. Zmianom uległa również gramatyka — język stał się bardziej analityczny — a wymowa prawdopodobnie właśnie w tym okresie wzbogaciła się o głoski /z/ i /zj/ (słowa takie jak vision, pleasure, to refuse). [6]
Proces zmian był nierówny, szybszy na południu, wolniejszy na północy, co doprowadziło do powstania całego spektrum lokalnych dialektów. Dopiero pod koniec średniowiecza, wraz z upowszechnieniem się druku, dialekt londyński zaczął zdobywać przewagę, dając początek współczesnej angielszczyźnie. William Shakespeare, pisząc pod koniec XVI wieku, korzystał już z języka, który nazywamy wczesnym nowożytnym angielskim. Tylko daleko na północy, na nizinach południowej Szkocji, średnioangielskie dialekty przetrwały i wyewoluwały we współczesny Scots: szkocki-germański (dla odróżnienia od szkockiego-gaelickiego).
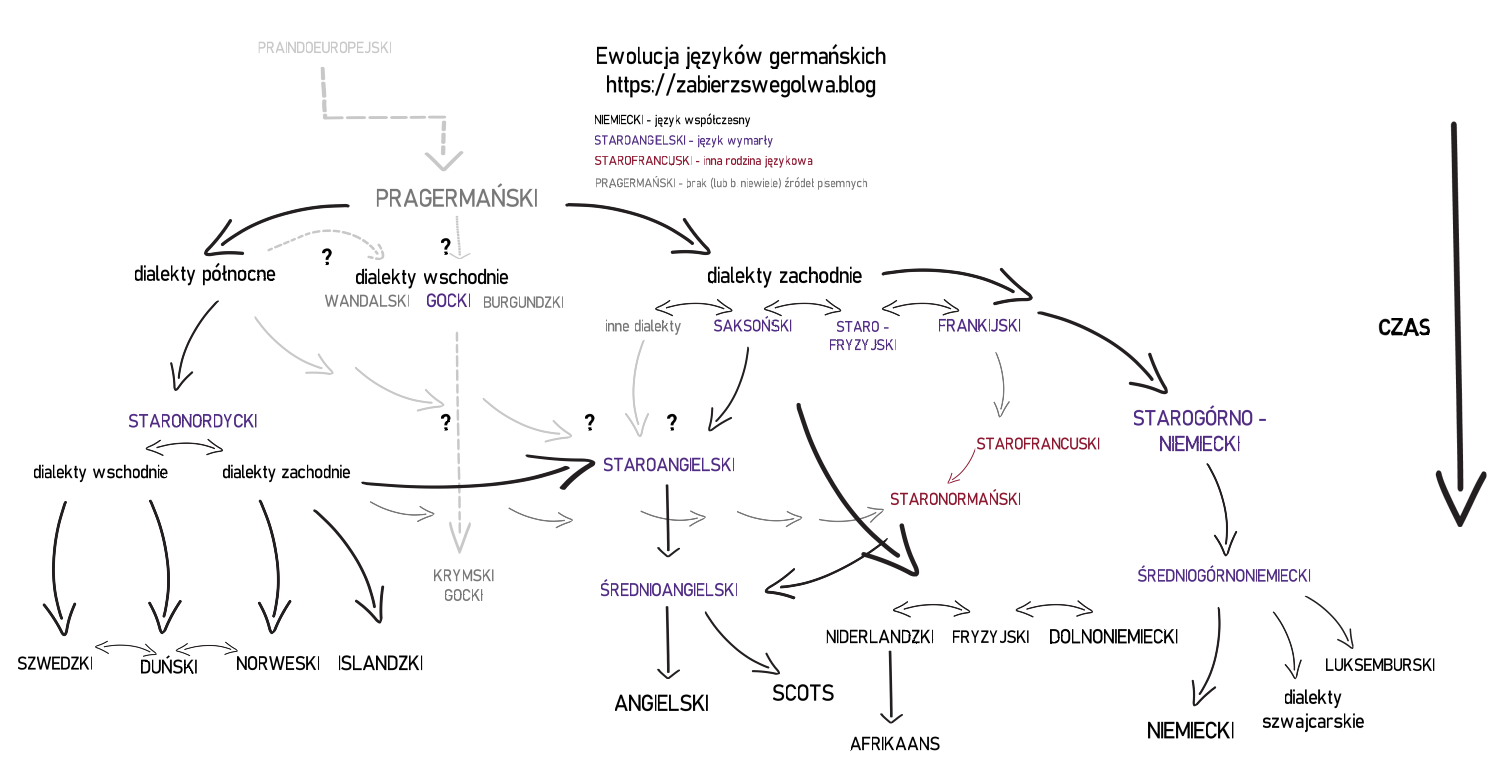
Diagram przedstawiający genealogię języków opisywanych w tekście.
Również jako animacja
Wróćmy jeszcze na kontynent. Pod koniec średniowiecza z dialektów wybrzeża Morza Północnego zaczęły wykształcać się nowe języki: niderlandzki i fryzyjski na zachodzie oraz tzw. dolnoniemiecki (niederdeutsch, plattdeutsch) na wschodzie. W XIV wieku, u szczytu potęgi Ligi Hanzeatyckiej, język średniodolnoniemiecki rozbrzmiewał wzdłuż Morza Północnego i Bałtyku, przez Gdańsk, aż po Estonię. Z czasem jednak pozycja Ligi osłabła. Na zachodzie język niderlandzki i fryzyjski utrzymały dominującą pozycję (niderlandzki dał nawet początek jeszcze jednemu językowi z tej grupy — Afrikaans), ale dolnoniemiecki, choć przetrwał, utracił uprzywilejowany status w kulturze i handlu na rzecz języka, który wrócił na północ po długim czasie niezależnego rozwoju u podnóża Alp: języka górnoniemieckiego (hochdeutsch).
Podczas gdy Skandynawia, Anglia i wybrzeże Morza Północnego na zmianę handlowały i walczyły ze sobą, środkowe i południowe Niemcy pozostawały zwrócone w zupełnie inną stronę. Mieszkańcy tych terenów byli potomkami plemion, które wywędrowały na południe być może jeszcze w drugim i pierwszym stuleciu przed naszą erą, choć na podstawie starożytnych źródeł (Strabon, Juliusz Cezar) nie jesteśmy w stanie stwierdzić ze stuprocentową pewnością, czy Cymbrowie i Teutoni, z którymi Rzymianie starli się w latach 113-101 p.n.e., byli Germanami czy Celtami [7]. Graniczyły ze starożytnym Rzymem, a następnie znalazły się w granicach imperium Karola Wielkiego, a po jego rozpadzie — Świętego Cesarstwa Rzymskiego. To tutaj, w klasztorach od Aachen po Jezioro Bodeńskie, rozwijała się literatura i język starogórnoniemiecki. Najsłynniejszym tekstem w tym języku jest fragment Przysięgi Strasburskiej, dokumentu z 842 roku, poświadczającego sojusz braci, Ludwika II Niemieckiego i Karola Łysego. Przez kolejne stulecia Święte Cesarstwo Rzymskie, które powstało z włości Ludwika, koncentrowało się bardziej na sobie oraz na relacjach z Francją i Italią, niż na kontaktach ze swoimi północnymi rubieżami. W konsekwencji wymiana handlowa i migracje ludności okazały się niewystarczające dla unifikacji języka na terenie całego kraju. Swój udział miała też zapewne geografia południowych Niemiec — góry, doliny oraz dwie wielkie rzeki: Ren i Dunaj — ułatwiająca izolację lokalnych społeczności. [8]
Przełomowym momentem dla popularyzacji, a równocześnie ujednolicenia języka górnoniemieckiego, była reformacja. W 1534 roku Marcin Luter przetłumaczył Biblię właśnie na ten język, a dzięki prasie drukarskiej mogła ona zostać szybko skopiowana i trafić w każdy zakątek Niemiec. Stopniowo, w miarę upadku Ligi Hanzeatyckiej oraz bogacenia się południa Niemiec, język górno-niemiecki zyskiwał na znaczeniu, a dolno-niemiecki zaczynał być postrzegany jako język rybaków i drobnych mieszczan.
Nie oznacza to jednak, że współczesny język niemiecki to monolit. Ta historia wyjaśnia jedynie, dlaczego różni się on tak wyraźnie od innych języków germańskich. Święte Cesarstwo Rzymskie nigdy nie miało jednego centrum: Austria, Prusy, wybrzeże Renu, i Szwajcaria, zawsze były osobnymi ośrodkami kulturowymi. Mamy więc obecnie do czynienia zarówno z różnymi standardami językowymi w Niemczech, Austrii, Szwajcarii i Luksemburgu, jak i z lokalnymi niestandardowymi wariantami i dialektami. Język luksemburski, wywodzący się ze średniogórnoniemieckiego, ma w Luksemburgu status osobnego języka, na równych prawach z niemieckim. Dialekty szwajcarskie nie mają takiego statusu, ale i tak są zupełnie niezrozumiałe dla przeciętnego Niemca. Niemieckie landy pozostają dumne ze swoich dialektów, nawet jeśli tylko niewielki procent mieszkańców potrafi się nimi poprawnie posługiwać, a dla większości znane różnice ograniczają się do specyficznej wymowy i kilku zabawnych synonimów. Również w Polsce — w Wilamowicach pod Bielsko-Białą — zachował się osobny dialekt górnoniemiecki, sprowadzony tu w XIII wieku przez osadników z zachodu. Obecnie prawie wymarły, ale trwają próby rewitalizacji.
Maciej Gorywoda mieszka w Berlinie, gdzie uczy się niemieckiego i francuskiego. Jest autorem bloga językowo-historycznego “Zabierz Swego Lwa”. Do tej pory blog koncentrował się na nauce francuskiego i historii średniowiecza, od nowego roku autor ma w planach poszerzenie tematyki o język niemiecki i Niemcy, z naciskiem na wydarzenia tworzące naszą wspólną europejską historię.
Dodatkowe materiały:
A “Old Norse and Old English”, ⦁ “Goths and Huns in Old Norse”, Jackson Crowford, U. of Boulder, Colorado
B “Germanic Languages of the World: Introductory Overviews”, Alexander Arguelles
C “The Gothic Bible: a reading of Matthew 27 in the Gothic language”, Jordan Ashley Moore
D “The Wulfila Project” – Biblia w języku gockim z tłumaczeniami na angielski i niemiecki
E “A Grammar of Proto-Germanic” – Winfred P. Lehmann
Bibliografia:
[1] “Perfect Phylogenetic Networks: A New Methodology for Reconstructing the Evolutionary History of Natural Languages”, Luay Nakhleh, Don Ringe, Tandy Warnow.
[2] “Runes and Germanic Linguistics”. Elmer H. Antonsen
[3] “Upadek Cesarstwa Rzymskiego”, Peter Heather
[4] “The Romance Languages”, Rebecca Posner, pp. 24-29
[5] “Romance Languages, A Historical Introduction”, T. Alkire, C. Rosen
[6] “Phonological Change in English”, Raymond Hickey
[7] “Climate and the Collapse of the Roman Empire | Part 3a: The Cimbrian War”, Brandon Lee Drake, U. of New Mexico
[8] “The Holy Roman Empire, a thousand years of Europe’s history”, Peter H. Wilson







 Przez jeden tydzień w marcu 2017 roku szwedzkie media zdominowała wiadomość o tym, że Szwedzi najwyraźniej mają problemy z gangsterami. A także z awokado, muffinkami, bajglami, tortillami oraz… zombie! Omawiane w prasie i w telewizji problemy nie dotyczyły oczywiście ani przestępczości, ani kuchennych rewolucji, ani tym bardziej postaci z horrorów. Chodziło o problemy językowe. A konkretnie o to, jak po szwedzku powinna brzmieć forma mnoga tych rzeczowników.
Przez jeden tydzień w marcu 2017 roku szwedzkie media zdominowała wiadomość o tym, że Szwedzi najwyraźniej mają problemy z gangsterami. A także z awokado, muffinkami, bajglami, tortillami oraz… zombie! Omawiane w prasie i w telewizji problemy nie dotyczyły oczywiście ani przestępczości, ani kuchennych rewolucji, ani tym bardziej postaci z horrorów. Chodziło o problemy językowe. A konkretnie o to, jak po szwedzku powinna brzmieć forma mnoga tych rzeczowników.





 Autorką wpisu jest Dagmara Bożek-Andryszczak – tłumaczka i lektorka języka rosyjskiego. Autorka bloga o tłumaczeniach i języku rosyjskim
Autorką wpisu jest Dagmara Bożek-Andryszczak – tłumaczka i lektorka języka rosyjskiego. Autorka bloga o tłumaczeniach i języku rosyjskim